The Four AI Waves - The Practitioner Perspective
The following text is an excerpt from my book ChatGPT: Undressed & Unadorned - The Truth about ChatGPT in Talent Acquisition (you can follow the link to get a free copy).
My first experience with machine learning was almost ten years ago, in 2013. Since then, I have worked on delivering more than 50 AI-powered projects for companies in the HR Tech and Online Recruiting industry like Experteer GmbH, Jobware AG, Jobiak, Jobiqo, Getin GmbH, Ofir, Jobsync, my job boards - Crypto Careers and Web3jobs and many more.
Boy, have things changed in the past decade.
My first experience building AI-powered products
I was a product manager for a job board with a massive team of specialists (over 80 people) who classified jobs, industries, career levels, etc. The project aimed to integrate a simple SVM prediction service in the back end that suggests the job category to the internal team. Back then, Python was not a thing yet, and we wrote the service using Ruby from scratch. Today, a simple OpenAI API call costing less than 1/100 of a cent can do the exact prediction. What we did was also not considered AI - we just called it machine learning.
From my perspective as a practitioner, we have seen four waves of AI over the last ten years. ChatGPT is a natural extension of those past trends focused on making AI accessible to businesses and consumers. These four waves are my definitions and are not to be considered academic or official.
The four waves of AI
Four criteria drive AI adoption. The first two are visible in the following graph, where you will see two axes: value and complexity. Two additional dimensions are also critical, but humans are not great at reading 4-dimensional graphs, so let's talk about them: data requirements to train models and cost of operations.

So, how does each wave compare to those four criteria?
The first AI Wave
Wave 1 is the period I initially started working with AI. My first AI product role aimed to build text classifiers for job boards in 2014. It was hard because the technology was not open-source, no one was using Python, and you needed a lot of data to reach acceptable accuracy—for example, a text classifier with 20 classes needed about 1000 samples per class.
Deployment and managing these models was arduous and time-consuming. There was no standard infrastructure - you had to maintain your servers and build your API layers.
Second AI Wave - Open Source Explosion and Transformers
Wave 2 happened around 2016-2018 and combined multiple technological innovations and trends. A robust open-source community emerged and adopted Python, a programming language that is very simple and easy to learn. The community saw the complexity of using the (almost non-)existing machine-learning tools and worked hard to make them more user-friendly.
Improvements to hardware made the training of Deep Learning models more realistic. Hugging Face and Fast.ai became two of the most popular Deep Learning repositories on GitHub, making it easy for data scientists to use pre-trained models with a few lines of code.
The most significant change, however, came in 2017 when researchers from Google published the most influential paper in deep learning - Attention is all you need. A year later, they released BERT, and the introduction of the Transformer infrastructure changed the natural language processing landscape forever. BERT was a breakthrough foundational language model that enabled the training of text classifiers with significantly fewer data at a fantastic accuracy.
Language models can capture more meaning from the text, drastically reducing the required training data. For some projects I worked on, we retrained and benchmarked BERT-based text classifiers against the original models, and we got similar performance with just 20% of the training data. This was groundbreaking, and this is when the golden age of deep learning started.
Continuing the example above, a text classifier with 20 classes now needs, on average, 100-200 samples per class to provide exceptional accuracy.
Third AI Wave - Explosion of AutoML
In parallel, a third Wave of AI development was already emerging - AutoML.
Non-tech people are not great at data engineering, training and deploying models and operating them. The challenge was still to find a way to bring machine learning and AI closer to PMs and business-driven people. How could that be done? Make it more accessible, of course.
Not only that, but the DevOps side of ML (MLOps) was still challenging for data scientists, even though the OS community was constantly seeking ways to make it easier.
This was when the AutoML trend was born.
In 2017 and 2018, I started seeing the first AutoML products offered to non-tech people, which were terrific. We could build ML-powered product prototypes in a few hours rather than days.
Here are two slides from a presentation I made during RecBuzz in Berlin back in 2018:
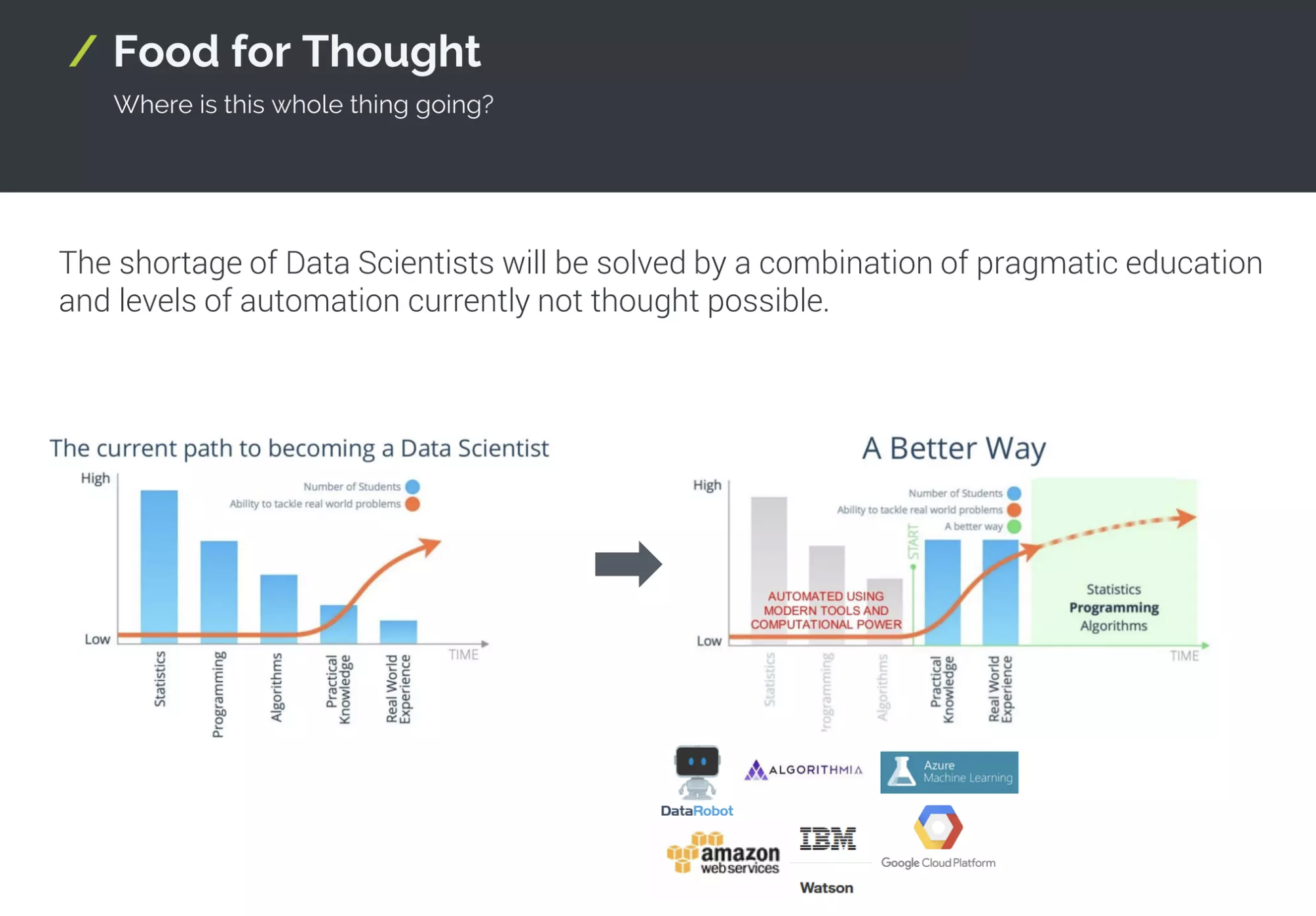
The main message was that we will soon have the technology to train a model and deploy an inference API with a few clicks. Indeed, this did happen, and today, we have hundreds of products on all major cloud providers - Google Vertex, Sagemaker Autopilot, BigML, Azure AutoML, and many more.
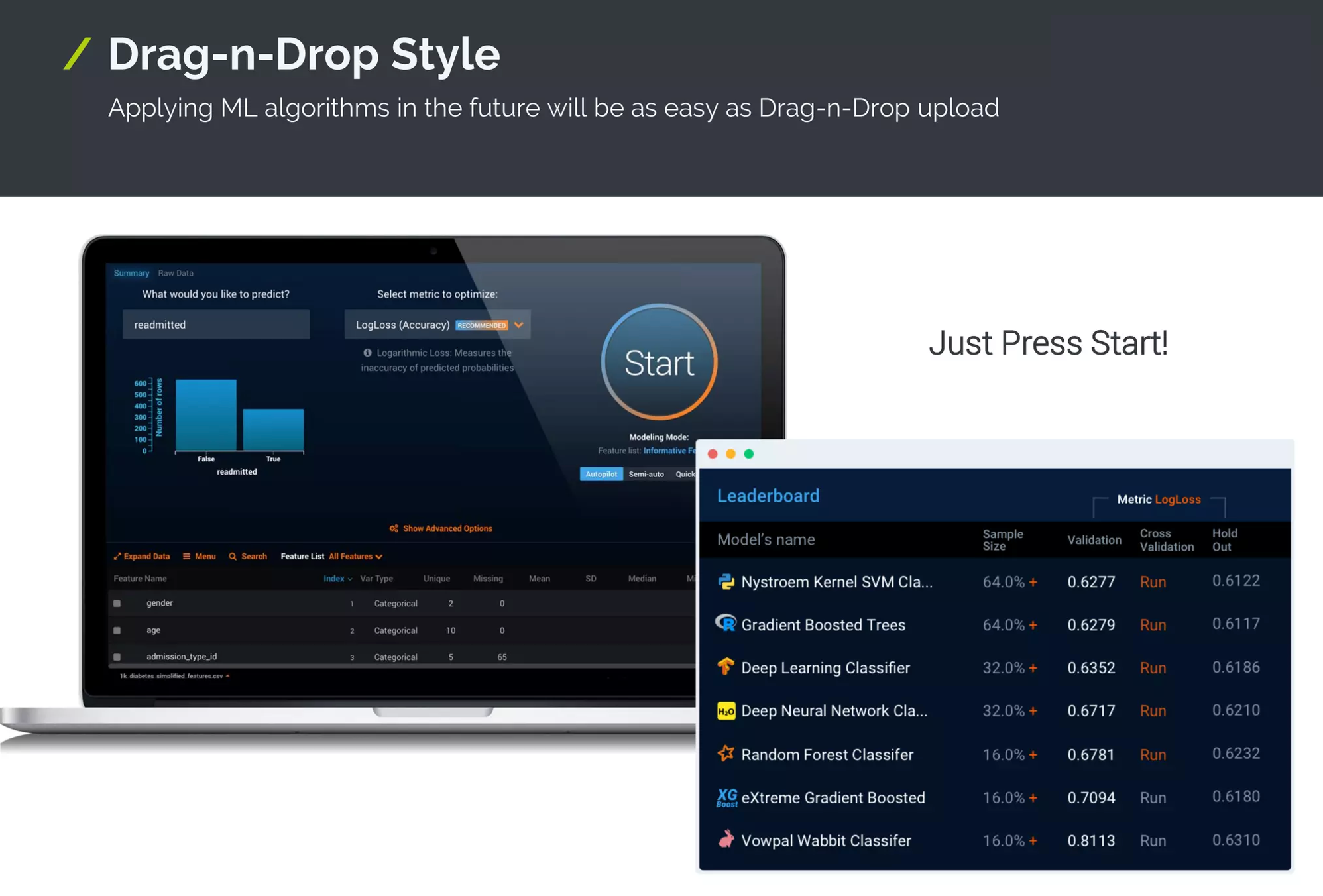
The beauty of AutoML is that you can dump labeled data in a cloud and let the machine figure out everything for you - it would choose the algorithms and preprocess the data, deploy a trained model for you in the cloud and give you an API. AutoML will go even so far as to scale and descale the instances behind the API based on the load, optimizing your costs.
This wave was impactful and transformational for many companies and AI product managers, including me. It enabled me to build and operate two niche job boards in a few hours of effort a week. It also allowed companies to create models with less data because the machine learning used to preprocess the data and select the algorithm was way more advanced than humans.
Compared to the models I built in 2014, I needed 100 times less data to get the same results. The cost of operating models also constantly decreases due to the competition in cloud computing.
The same example with the 20-class text classification product can be solved with AutoML with 30-40 samples per class.
Fourth AI Wave - Generative AI and the API-aization of AI
Wave 4 is where we are now with ChatGPT and Large Language Models. Compared to the previous ones, the main difference in this AI wave is that you don’t have to do any data engineering, training and deployment.
But the most significant difference is that you don't have any training data - you get a UI/API that you can query with your requests. This is groundbreaking for a variety of reasons.
I can give ChatGPT a job description and a list of categories and ask it to predict a category without examples. In most simple cases, it will succeed. It is an entirely new paradigm, and make no mistake, it will drive adoption. This is called zero-shot classification and has been the NLP dream for the last five years, but ChatGPT and, specifically, the underlying GPT-4 model made it possible.
Here is an example where I use zero-shot classification, and ChatGPT correctly classifies an Organic Search Senior Manager job in the marketing category. This is not an easy task, as Organic Search is a specific function of Online Marketing, but the AI correctly guessed the category.

Of course, it is not as easy as it sounds, and generative AI has several drawbacks. Traditional machine learning models can provide accuracy with each prediction, which can be used to decide which predictions are good or bad. Such evaluation is not possible with generative AI and GPT models. Then there are the hallucinations, the costs of the API at scale, the legal risks, and so on. In the example above, if you want to use this in production, you need to build additional guardrails to ensure that the model is adequately grounded and does not predict categories not part of the list.
Ok, so this is a lot of text and some nice assumptions, but do I have some real business cases to tell you about and how they were impacted by these waves.
Case Study - First AI Wave on the example of classifying jobs using machine learning
This project was one of my first experiences building an AI-powered product in 2014 - the first AI wave I talked about earlier.
The company, a niche job board, had a team of about 80 data analysts who would go to various companies’ career pages and hand-pick the jobs that fit its niche. They would then enrich the job postings by assigning experience level, category, industry, location, and additional metadata. The matching engine could then suggest fully classified jobs to candidates or job seekers themselves could find them on the job board using its filters.
It was essential to classify the jobs correctly because the system had a salary estimation process that used the taxonomy to calculate it. So, if the classification was wrong, the salary would also harm the matching process and waste time both for the recruiter and the candidate. The Taxonomy here was very complex. It spanned over 20 categories, 600+ industries in four levels and eight different experience levels. Not only that, but the job board was also operational in most Western European countries, so 7 different languages.
The company required a diverse team of analysts who were able to speak different languages and deeply understand industries and international labor markets to run this operation. That said, the process was still relatively simple — read a text and make a decision. We also had a dataset with millions of jobs annotated by humans, which was a great start. This is a perfect use case for AI.
As I outlined in the first Wave description, we did not have open-source tools back then. It took us eight months to finish the project – seven languages, four classifiers, and an accuracy of about 90%, which was on par with the human performance.
It took us around six more months to completely rebuild and decouple the back-end platform and rebuild the database and data models to enable the AI-classifiers integration. In this process, we discovered that we need more AI classifiers, for example, ones looking at the job title, to reduce the number of jobs that did not match the niche criteria.
Bottomline, after two years and a seven-figure investment, the department went through a tremendous transformation:
- Team size reduced by 80%
- Operational costs were reduced by 70%
- Job inventory grew 4-fold
- Job processing capacity increased 100-fold
The biggest surprise was a new revenue stream of €150-200k / year. The department was suddenly a profit center, not a cost center.
Once we had automated the job processing and classification tasks, the company could import feeds from job aggregators, programmatic advertisers, and other job boards at scale. This functionality was impossible with the previous setup because each job had to be checked manually and a decision made regarding its fit with the niche. It was beyond human capability to do that when importing millions of jobs daily, but with AI, this business case was now possible.
This is often a nice bonus when introducing AI into a process — you tend to immediately see new opportunities for cost saving, revenue or just plain service improvement.
This transformation would not have been possible without AI, but it was also a long and expensive process, mainly because:
- There were very few open-source models and tools available
- We needed a lot of training data and had to clean a lot of data alone. The dataset used in the training was worth €2-3 million.
- Machine Learning algorithms for natural language processing were not that advanced.
- There were hardware limitations and complex infrastructure requirements to run the models.
The impact of the 3rd and 4th AI Wave on job board processes
Here is a second case study - the job boards I operate - Crypto Careers and Web3jobs.
We have traditional machine learning classifiers and we use generative AI for zero-shot classification to enrich jobs with the following information:
- Category
- Experience
- Skills
- Salaries
- Location
Not only that, but we also use generative AI to help us with our job scraping, evaluating if new companies match our niche criteria. In the process, we also generate user-friendly company pages with a description of the business, benefits and tech stack:
AI is also the core technology in our sales outreach campaigns, which are fully automated.
All of this at the unthinkable monthly infrastructure cost of €100 (yes, half of it goes to OpenAI).
Conclusion
Today's AI technology can solve many problems without a training dataset, infrastructure or much technical knowledge.
The 4th AI Wave enables companies and solopreneurs to build exceptional and complex AI-powered products at a low cost quickly, efficiently, and scalable.
Of course, we have to discuss the usual risks associated with using AI, specifically generative AI - data ownership, data processing practices, privacy and lock-in pricing effects. Some are not fully understood, but this is part of technology development.
Exciting times!