Beyond the Hype: Unpacking the Real Challenges of Integrating Generative AI in Business
Anyone claiming companies will rapidly adopt generative AI for day-to-day processes does not know what they are talking about. Let me tell you why.

First, although generative AI is a fascinating technology with exceptional use cases, it has a significant issue for business use – hallucinations. I know it has been discussed a lot, so we don’t have to repeat what has already been said.
This is a problem for any serious business. For example, you cannot run your customer support if the LLM makes up suggestions to customers based on non-existing products, right? Even worse, the model might suggest actions outside of what your organization deems good practices (for example, giving refunds after 31 days).
Of course, the example above could be better because you will only implement an LLM for customer support tasks with some additional steps.
Luckily, there are options to mitigate hallucinations.
Using RAG and Fine-Tuning to reduce hallucinations
Let’s look at two of the most enterprise-ready use cases where hallucinations can be (somehow) controlled: RAG and Fine-Tuning.
RAG example for a knowledge database
RAG is a straightforward concept:
- Take a long text and split it into pieces
- Create embeddings for each piece and store them (most likely in a vector DB)
- When a question comes in, create embeddings for the questions
- Find the most similar embeddings of sections from the long text, maybe the first 3 or 5
- Send these 3-5 pieces along with the question to the LLM
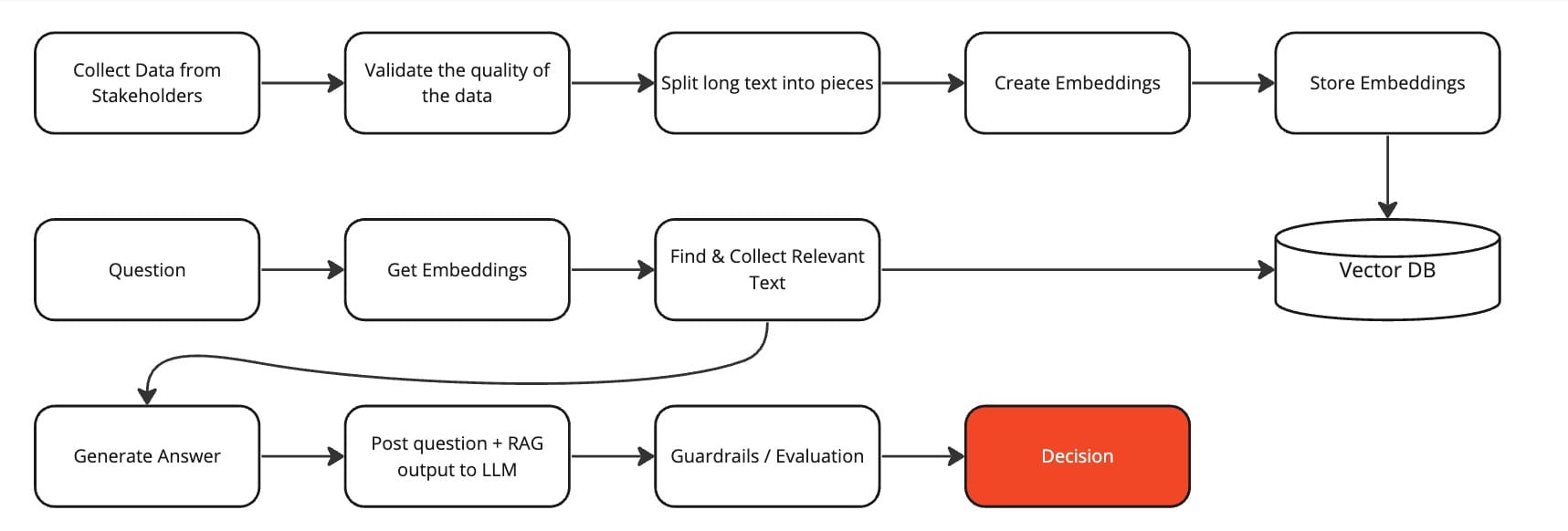
For the context of this article, I will ignore all technical complexity that comes along with this and will usually trigger the legal and security department of any large company, for example:
- Which vector DB
- Where will the vector DB be hosted and the data stored
- What API / model to use for the embeddings
- If you use embeddings from an API, how do you clean private data
Let’s look at an often-repeated use case for RAG: use your company-wide knowledge database and build a bot that uses RAG to answer questions from workers or new employees. Save time in training, onboarding, and email.
Makes so much sense.
But let me ask you this - how many companies do you know that have an up-to-date, cross-department knowledge database stored in a centralized place? What about one being vetted so you can trust the content and this content is constantly updated?
Very, very few.
So, let’s look at the second option - fine-tuning.
Fine-tuning example for a customer support bot
Building a chatbot that answers customer questions with LLMs is an absolute no-brainer for a large company offering hundreds of products. Not surprisingly, this is also the most quoted use case for LLMs today in the enterprise. Unfortunately, as brilliant as foundational LLMs are, they are not familiar with your internal products, policies and decision framework by default.
This is where fine-tuning comes in. This process adjusts the model's existing parameters to make it more adept at handling tasks related to this new, focused dataset.
So, to fine-tune an LLM, you need targeted training of a pre-trained model using a specific dataset relevant to the desired task, like customer support for a particular company.
The fine-tuned model is then evaluated and adjusted based on its performance on a separate validation dataset (a golden dataset), effectively transforming it into a tool specialized for a particular domain or task while maintaining its broad language understanding. You also have to ground the model and think about all escalation cases. This is not a small effort.
What is the common for both cases?
The problem is that for both, you need good data.
The data problem in AI-projects
As someone who has worked on over 50 AI-powered products for over ten organizations in the HR Tech space, these problems sound familiar.
Before generative AI, we called them data collection, feature engineering, and model training. Funnily, the issue with most ML projects is rarely the algorithm selection, but these three steps and everyone who worked in this space know this.
My take is that most companies lack this data in a good enough quality. All the power of GPT-4 will only help you if the data you use for RAG is updated and properly represents your company policies.
Similarly, try to get ten people from 3 different departments aligned on handling customer support questions to get usable training and validation data.
Even worse, in most cases, you will have to fight with five mid-level managers who have built silos around their departments and have zero willingness to share any data. I have experienced this one too many times in my career, and plenty of projects ended in drawers because of this.
Last but not least, most knowledge databases in enterprises are emails. However, emails are not a consistent source of truth because they change over time.
Summary - generative AI adoption hurdles
In this blog post, I critically examine the challenges of adopting generative AI in business environments, emphasizing the issue of AI 'hallucinations' and the complexities involved in implementing technologies like RAG (Retrieval-Augmented Generation) and fine-tuning for enterprise use.
I have also taken a deep dive into the crucial need for high-quality, up-to-date data and the difficulties businesses face in data collection, cross-departmental collaboration, and overcoming managerial silos.
Now, I want to clarify one thing – generative AI will be adopted in enterprises; there is no doubt about this. I am solely skeptical that it will be as fast as AI influencers claim.