RAG (Retrieval Augmented Generation) Deep Dive - Implementation, Challenges and Use-Cases for Job Boards and Aggregators
RAG, or retrieval augmented generation, is often quoted as a simple, no-brainer generative AI use case for the enterprise. I can't entirely agree.
In this article, I will present the challenges of implementing RAG systems in the enterprise and discuss potential use cases for RAG implementation for job boards and aggregators.
Let’s cover the basics!

What is RAG in the context of a generative AI system?
RAG, or Retrieval-Augmented Generation, is an AI technique to improve responses. It first finds relevant information from a database (ground truth) and generates a response based on a prompt with that pertinent information. This method helps AI provide more accurate and contextually relevant answers.
Often, people claim that this solves hallucinations. It does not, but it might reduce them.
How can enterprise customers utilize RAG technology?
When used correctly, RAG can help enterprises provide precise, context-specific responses. This is a great use case for automating customer support and is often quoted as a no-brainer.
So, what are the challenges?
There are six challenges with implementing RAG in the enterprise:
Technical challenges
Building a RAG system requires an extensive combination of skills and technology expertise – setting up a database, chunking text, creating embeddings, building the retrieval function, and prompt engineering.
What does that mean in concrete, non-technical terms?
Imagine it like putting together a complex puzzle where each piece represents a different technology task. First, you must organize a massive collection of vetted information into a database. Then, you have to break down and sort all the text in this library into smaller, more manageable pieces. Next comes a technical step where you make this text understandable to computers using embeddings and vector representation. After that, you create a system to search and find the correct information in this database quickly. Lastly, you need to be clever when asking the system questions (or giving it prompts) to get the best answers. This lot of tech knowledge will make the system work smoothly.
I expect this challenge to be streamlined quickly with standardized software, which will rapidly commoditize these components. Many providers are trying to offer a service that waits for you to upload your data and just start.
Accuracy of retrieval
Challenge two is ensuring the relevance and accuracy of retrieved information. This is crucial - if the retrieval component sources incorrect or outdated information, the generated responses will be flawed. Like the process above, I expect this to be part of a standard cloud-based or on-premises RAG system.
Ground truth and data quality
Challenge three is maintaining a comprehensive, up-to-date, ground-truth database for retrieval. This ongoing task demands constant updating and curation, and the larger the company, the more difficult it is to establish ground truth.
Data Privacy
Challenge four is data privacy. The enterprise has plenty of legal restrictions on what user data can be sent to ChatGPT or a third-party-operated LLM. Implementing rules regarding when and what personal data can be sent to the model can also handle the data privacy issue.
Companies can also set up local LLMs and heuristics to clean private data from a prompt or extraction.
Prompt Engineering
Challenge five is to train and ground the model to understand the queries and produce appropriate responses. This is usually handled with fine-tuning and some form of prompt engineering.
Now, the prompt engineering part is relatively straightforward. However, having a good collection of input and expected output examples for fine-tuning would be best. Trust me, most companies don’t have this. It is an effort to generate them. Although Open AI has enabled fine-tuning with just a few clicks, understanding the meaning of a fine-tuning metric is not trivial for someone not from the data science world. This can lead to issues downstream.
Quality Process
After ten years of building AI-powered projects, I can tell you that the quality part is the one that almost always gets postponed after the launch 😊
So, let’s talk about the last challenge—setting up a proper quality system. Anyone who has worked on projects inside an enterprise knows that asking the same question three times will yield three different answers. Sometimes, it is politics; other times, it is just a lack of knowledge sharing.
With this in mind, the quality-controlling process becomes critical.
This is why RAG systems require well-defined quality metrics. Defining these metrics alone is a difficult task—should you focus on the quality of the generated content, user satisfaction, or the accuracy of the retrieval function?
The quality process also requires a feedback mechanism, where employees or customers can report inaccuracies or issues with the output. This feedback might require manual action and human intervention. Therefore, human oversight becomes essential.
Using the feedback for such a system to drive iterative improvements is also essential – fine-tuning, prompt engineering and updating the ground-truth database are all tasks that are not trivial.
What are some RAG use cases for job boards and aggregators?
In the world of AI, specifically generative AI, people like to find a place for a solution or technology without considering whether it makes sense to use this tech in the first place.
These are the only three cases that make sense to me right now.
Intelligent Q&A Systems for Job Seekers
This is an excellent use case if you have content related to career coaching, resume writing tips, interview guidance, etc.
You can retrieve the relevant content from your career advice database, and with RAG, you can offer more personalized and hypothetically precise career advice to candidates. You can even use their profiles and job history to augment the generated suggestions for career development, additional skills to acquire, and potential career paths.
However, there are plenty of pitfalls in building this system. Without getting too much into details, I recommend reading:
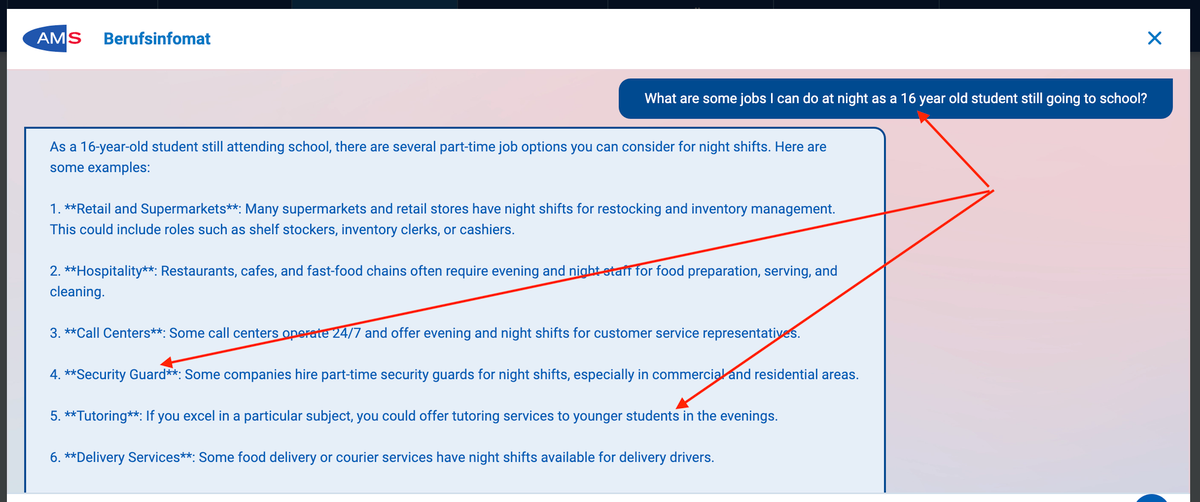
Intelligent Q&A Systems for B2B Customers
Implementing a Q&A feature where employers can get immediate, accurate responses to their queries is a great idea if you have a detailed, annotated collection of questions and answers from your CS team.
RAG can provide answers by retrieving information from these FAQs and product documentation in real-time, significantly reducing the time for response.
These chatbots can theoretically provide real-time, accurate answers to job postings, product features, and platform navigation queries. Many job board owners are familiar with this issue – the questions are often simple and require a quick 1-2 lines of text.
However, the quality of the responses is still greatly dependent on the quality of your FAQ database.
Also, I recommend having guardrails in place to not let the bot answer any questions about pricing and discounts, as it happened once:

Automated Job Description Generators
If you have followed my content, you know I am a vivid opponent of generative AI for job description generation. One of the main issues I have with this is that most people would query GPT with a basic prompt and get a generic job description with questionable quality. Not only that, but due to hallucinations, you might receive suggestions for skills and tasks which are not relevant to a given job title.
Assuming you have a good database of “good” job descriptions, RAG can assist in creating new job descriptions.
In the first step, the system will collect input from the employer about skills, requirements, etc. In the following steps, the RAG system will pull a relevant job description from the database and build a prompt with the requirements profile and the example job description.
Hypothetically, this will result in significantly better job descriptions than any raw Chat-GPT prompting because of the good underlying data. Still, the underlying requirement - having examples of "good job descriptions"- is not trivial.
Conclusion
The most significant issues with implementing RAG systems are the ground-truth database that companies maintain and update constantly and the quality process, including building and following a quality process. For job boards and aggregators, the use cases for RAG systems are relatively limited and primarily relevant platforms with extensive Q&A databases or career coaching content.