The new EU Pay Transparency Directive: a hidden opportunity for Job Boards
In this article, I want to outline what the new EU Pay Transparency Directive is and how job boards can leverage it to improve their SEO and Search Results.
The EU Pay Transparency Directive is rolling out across member states. While much of the conversation focuses on compliance headaches (remember GDPR?), there's a significant opportunity for job boards that no one is talking about.
What are the key pillars of the EU Pay Transparency Directive?

The directive requires ALL employers - regardless of size - to disclose salary information to job applicants, either in the job posting or before the first interview. Now, this is quite important – it does not immediately mean that employers will start adding salaries to job descriptions, as they still have the option not to.
Also, member states are implementing this with varying degrees of strictness, and some companies will always choose to have the admin overhead but NOT publish salaries. However, the practical reality is that a substantial portion of EU job postings will include salary data, particularly as employers adopt the most straightforward compliance path: including it in the job posting itself rather than managing disclosure on a case-by-case basis during recruitment.
Member states must implement the directive by June 7, 2026, meaning this shift is happening right now.
While this will be a major headache for some, like GDPR, it's a competitive advantage for job boards that get their technical implementation right. Let’s explore why.
Why does salary data matter for job boards?
Salary data isn't just nice-to-have metadata. It's a competitive weapon for job boards that can extract and properly structure it. Here's why:
1. Salary data is a confirmed ranking factor in Google Jobs. Although Google has never explicitly stated that job postings with salary information receive preferential treatment in the Google Jobs algorithm, as someone who has been optimizing Google Jobs for over 7 years now, I know this is the case.
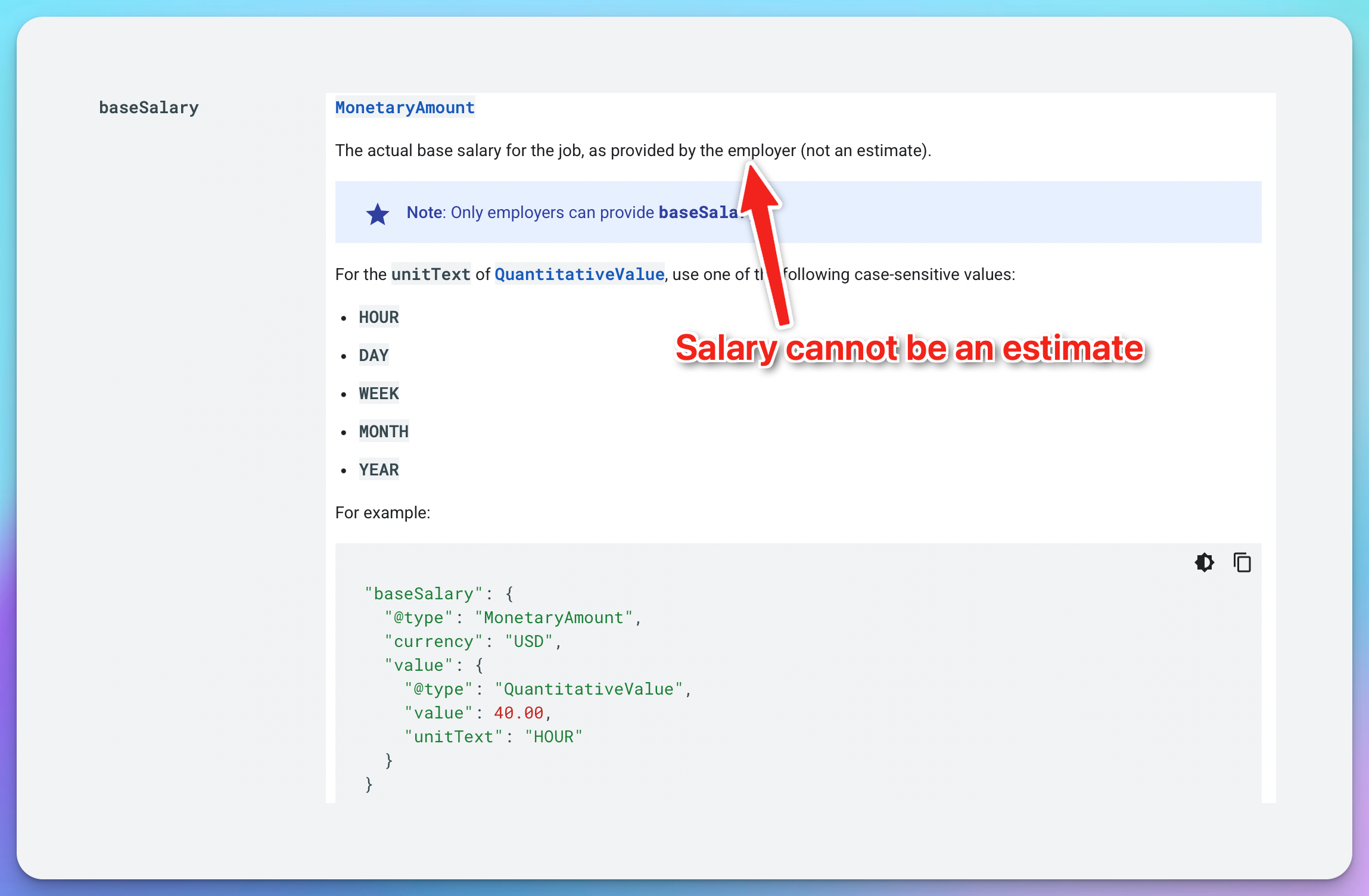
Salary present = better rankings = more organic traffic from Google Jobs.
This is especially true if your competitors are already extracting salary properly and you are not.
2. Salary data improves matching. Candidates with clear compensation expectations can self-select into appropriate roles, improving application quality and conversion rates.
3. Salary data provides additional filters in the UX. Filtering by salary range drives activity on your category pages and keeps users engaged longer on your platform, thereby improving those pages' rankings.
4. Salary data allows you to target specific long-tail searches. Queries like "jobs for teenagers at €16" or "€70k software engineer jobs Munich" become targetable with structured salary data.
So, if you're able to extract this data effectively, you will: increase your organic traffic, improve visibility on Google Jobs, enhance matching quality, and capture more keywords.
And remember, if you don’t, but your competitors are, you will actually see a decline in performance. Although many factors influence Google Jobs rankings, having an incomplete schema while others have theirs fully optimized is a problem.
5. Programmatic SEO Data. Having historical job data on salaries is a tremendous asset you can leverage to build complex salary reports programmatically, capture informational queries, and improve your topical authority.
Now that we have established why salary data is essential for job boards, let’s look at the current availability of this data in job postings.
Countries where salaries are present in job postings
Several European countries already have salary transparency requirements in place.
According to Indeed data reported by Euronews, the current state of salary inclusion in job postings as of May 2025 shows:
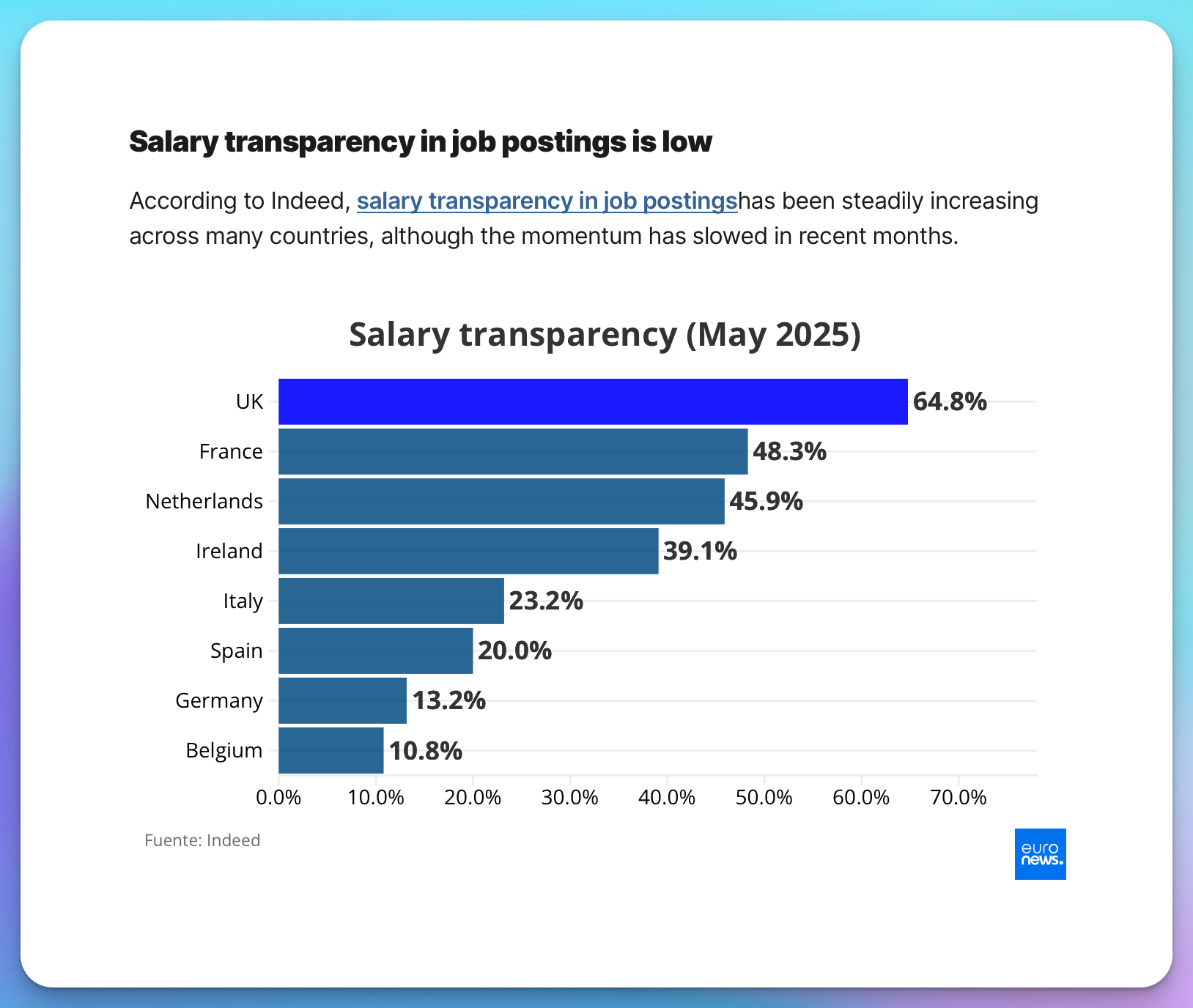
The UK has the highest rate at 65% of job postings, though this is voluntary rather than mandated.
France sits at 48% salary inclusion and has strong existing pay equity laws, with requirements for companies with 50+ employees to conduct annual pay audits.
The Netherlands is at 46% inclusion and has delayed full implementation of the directive until January 2027.
Germany, Italy, and Spain lag with less than 25% salary inclusion, but this will change dramatically once the directive is fully implemented. In Germany, especially, it is absolutely unthinkable to have a salary in the job description – something that has been puzzling me for years.
Austria has been the EU leader since 2011, requiring mandatory salary disclosure in all job advertisements. However, it is just a range, and many companies abuse this practice to be compliant without actually disclosing the salary (i.e., what does a range of €1000-€10000 help me?).

The trend is clear: salary data in job postings is becoming the standard across Europe, not the exception.
The technical challenge with salary data extraction at scale
But many job boards are struggling with the technical side of this transition, and salary extraction is a complex topic. Let’s review the usual ways of extracting salaries:
Back to basics - Regex
The traditional approach to salary extraction relies on regular expressions (regex). Job boards try to build pattern-matching rules to catch salary mentions:
€50,000 per year
£35k-£42k
45.000€ jährlich
€25-30 per hour
The problem becomes quite apparent when you look at all variables: regex quickly becomes a nightmare. You're dealing with:
- Multiple languages (German, French, Spanish, Italian, Polish, Dutch, etc.)
- Different formats (annual vs. hourly, gross vs. net, per month vs. per year)
- Salary ranges vs. fixed amounts
- Currency symbols and number formatting variations (€50.000 vs €50,000 vs €50t)
- Contextual phrases ("up to," "starting from," "competitive salary of")
- Edge cases like bonuses, benefits, and variable compensation are mentioned alongside the base salary
You could end up with thousands of regex patterns FOR ONE LANGUAGE only, constant maintenance, and still miss edge cases. It's not scalable across the 24 official EU languages.
Intermediary Options – Deep Learning and Machine Learning
Another approach that became popular with the advancement of neural networks and machine learning was first to classify text into entities, then classify the salary entity into its corresponding taxonomy.
However, this required absurd amounts of data to train on, and this was a problem if you wanted to scale to 4-5 languages. Not to mention maintaining two different classifiers…
The “modern” solution – it is all LLMs
The obvious modern solution? Use large language models to extract salary data. Just feed the job description to GPT or Claude with a “magic prompt” and ask it to extract the salary information.
But here's the problem: LLMs hallucinate.
When a job posting says "competitive salary" or doesn't mention compensation at all, generic LLMs will sometimes invent plausible-sounding salary ranges based on the job title and description. For a job board, this is worse than having no data—it's incorrect data that breaks user trust and creates legal liability.
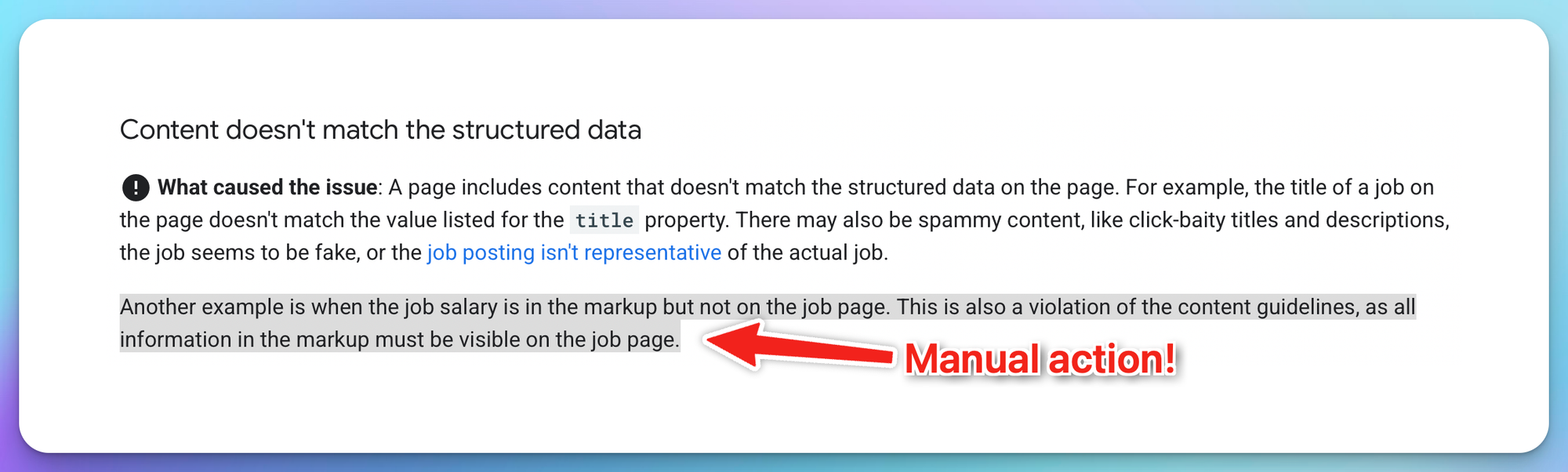
You can't have your structured data markup showing €65,000-€80,000 when the original posting never mentioned that range. Google can penalize you for it with an actual manual action, and users will notice the inconsistency.
And no, I did not make this up, Google literally states it!
The Hybrid Solution: Fine-Tuned Models + Traditional ML
The solution we've developed combines the best of both approaches:
Fine-tuned LLMs trained specifically on salary extraction tasks, with training data that teaches them to distinguish between explicit salary mentions and contextual clues. These models learn to output "null" when no salary is present rather than hallucinating.
Traditional ML validation layers that cross-reference extracted salaries with entity recognition against the parsed job description.
LLM validation layers are explicitly built to provide multiple sources of truth as additional trust signals.
Multi-language normalization that handles the complexity of European salary formats across all major EU languages—German, French, Spanish, Italian, Polish, Dutch, Czech, and more.
Format standardization that converts everything into a consistent structure for schema markup: annual salary ranges in local currency, properly tagged as gross or net.
This approach gives us:
- High accuracy (99%+ precision on salary extraction)
- Multi-language support for all major EU markets
- Scalability across millions of job postings through our scalable job data pipelines
- Extraction of additional information, like benefits
You might have noticed that the precision I am talking about is not 100%. This is because I don’t believe that there is a real approach that can guarantee a 100% correctness. However, if you provide a confidence score, you can choose not to use low-quality predictions.
Remember – in this context, a wrongly extracted salary is worse than a non-extracted salary.
The Implementation timeline for the directive
Ok, now we covered the basics, so when is this thing going to"live"?
Member states must implement the directive by June 7, 2026. That's only months away.
Job boards that get their salary extraction infrastructure in place now will have a significant head start:
- Better Google Jobs rankings throughout 2026
- More comprehensive salary filters than competitors
- Higher-quality matching and user engagement
- Coverage of long-tail salary-specific search queries
Those who wait will be playing catch-up while their competitors capture the traffic.
Our Job Data Pipeline Services
If your job board is facing challenges with:
- Extracting salary across all EU markets and languages
- Normalizing salary data for Google Jobs markup
- Scaling this across thousands or millions of listings
Our job data pipeline services are built specifically for these problems. We help job boards process and structure job data at scale to maximize their Google Jobs and SEO performance.
Not only that, but our Job Data Pipeline service supports the extraction of any required metadata - remote type, experience, education – you name it.
The technology stack combines fine-tuned LLMs with traditional ML approaches to deliver accurate, scalable salary extraction without hallucinations—across all major European languages and markets.
This hybrid approach allows us to scale fast and be flexible, while still offering unmatched precision.
The pay transparency directive offers job boards a chance to gain a ranking edge.
Make sure your technical infrastructure is ready to capitalize on it. Reach out to me via the contact form or on LinkedIn, and I will be happy to give you a demo.